The technical bottlenecks that break AI at scale (and how to fix them)

Amir Ouki
Managing Director,
Applied AI & Technology
If your pilot was optimized for the sandbox with clean data, static inputs, and fixed parameters, it’s likely not ready for production.
AI pilots are often designed to prove that something could work. But when it’s time to move from a single workflow to a production environment, that early prototype starts to break:
- Infrastructure can’t keep up with
- Data pipelines don’t hold up to the model’s demands
- Retraining logic isn’t defined or is manual
- Monitoring is nonexistent.
What was once a promising demo now needs to operate under the weight of live traffic, real-time data, governance requirements, and cross-team handoffs. This is what technical debt looks like when AI hasn’t been designed to scale.
So what are the typical technical bottlenecks that will break an AI product at scale?
1. Context-window constraints
Recognizing and overcoming token limits
Foundation models enforce a fixed “context window,” capping how many tokens you can process at once. Once you exceed that, you’ll see silent accuracy drops or outright failures, especially with long-form inputs or chained prompts.
How to fix it
Planning for token limits before launch guarantees you won’t discover a “hidden” ceiling under real-user load. Some of the most commons of dealing with context-window constraints include:
Retrieval-Augmented Generation (RAG). At inference, fetch only the most relevant passages rather than passing entire documents.
Chunking & sliding windows. Break inputs into overlapping segments so each request stays within token limits.
Long-context model variants. Experiment with open-source or commercial models built for extended context lengths.
2. Real-time latency
Designing for sub-second inference at scale
Most large models aren’t engineered for ultra-low latency. In a live, user-facing workflow, even a half-second delay can break SLAs.
How to fix it
Embedding these optimizations during development can help you hit your goals without massively sacrificing insight depth:
Model distillation & lighter backbones. Use a distilled or compact variant for real-time paths, reserving the full model for batch analytics.
Pre-computations & caching. Pre-generate embeddings or common partial outputs and cache them for instant retrieval.
Optimized prompt flows & parallel calls. Structure prompts to minimize generation steps, and parallelize retrieval plus response where possible.
3. Data drift & retraining
Building resilience for data and concept drift
Even the best model will degrade over time as input distributions and user behavior shift. Manual or ad-hoc retraining can’t keep pace; safeguards for both need to be in place from the start.
How to fix it
Including condition-based retraining into your CI/CD workflow keeps performance reliable (and auditable) without constant human intervention. The key principles of planning for data drift are:
Automated drift detection. Continuously monitor inputs and key output metrics, with alerts when thresholds are crossed.
Scheduled & event-driven retraining. Define clear rules: time-based, performance-based, or drift-based, which will trigger retraining pipelines automatically.
Regression-testing frameworks. Maintain evolving train-test splits and run contra-gression tests whenever data schemas or model versions change.
4. Version sprawl & traceability
Ensuring governance through model versioning and lineage
It’s easy to fork models and scripts for each use case, until you’re left with dozens of untracked versions and no clear ownership. These practices aren’t just hygiene; they form the foundation of trusted, enterprise-grade AI.
How to fix it
Centralized model registries. Record metadata for every build: version, training data snapshot, hyper-parameters, and lineage.
Input-output versioning. Log every inference request with its exact model version, data batch, and output, all of which are crucial for debugging and compliance.
Governance dashboards. Surface component ownership, rollback paths, and one-click redeploy options.
Don’t let technical debt kill a promising solution
Technical bottlenecks are invisible in the lab but glaring in production. To future-proof your AI builds:
Anticipate token limits with chunking, RAG, or long-context models
Optimize for sub-second latency via distillation and caching
Automate drift detection, retraining, and regression tests
Enforce traceability with registries, logs, and governance
In enterprise AI, the best-performing model isn’t the one that demos well. It’s the one that reliably delivers value at scale.
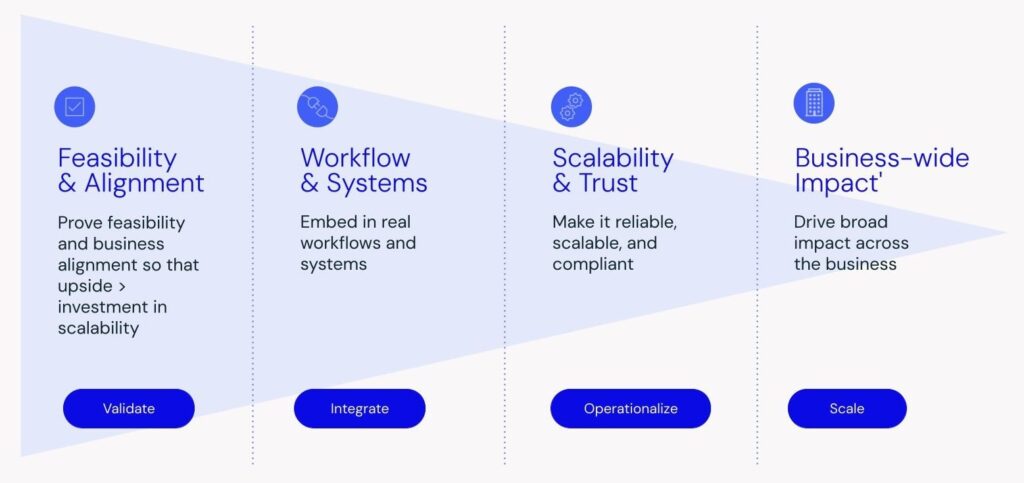
AI solutions built for commercial impact
From multi-agent orchestration to simulation environments for decision-making, we design and build AI solutions through clear, actionable stages.
Looking to build an AI solution that delivers real business value at scale? Let’s talk.

Managing Director, Applied AI & Technology
Amir leads BOI’s global team of product strategists, designers, and engineers in designing and building AI technology that transforms roles, functions, and businesses. Amir loves to solve complex real world challenges that have an immediate impact, and is especially focused on KPI-led software that drives growth and innovation across the top and bottom line. He can often be found (objectively) evaluating and assessing new technologies that could benefit our clients and has launched products with Anthropic, Apple, Netflix, Palantir, Google, Twitch, Bank of America, and others.