AI’s hidden crisis: Sprawl without transformation
And why we need a new AI governance approach, built for the speed and nature of AI.

Laura Stevens
Managing Director of Data & AI
These days, AI is entering companies through every open door: in product, marketing, legal, HR, ops, and sales or through open-source models, browser plug-ins, no-code agents, and everyday tools like Microsoft 365. A recent Gartner (November 2024) survey of approx. 451 senior technology leaders (including CIOs) shows that ~35% of AI capabilities are built by their IT teams. The rest will emerge at the edges, led by marketing teams, HR, operations, and more.
Put simple: the pace and pathways of AI, as a general purpose technology, are fundamentally different from traditional IT.
“AI isn’t knocking politely at the front door of IT. It’s streaming in through every side window.”
AI at the edge has a huge potential. If orchestrated properly.
This surge of edge experimentation holds huge potential. It’s where energy, creativity, and urgency live. But without orchestration, it rarely compounds into transformation.
Innovation at the edges is only valuable if it compounds into impact at the core: into shared capabilities, common standards, and enterprise-wide momentum. Especially in AI, the real value lies in scale effects: shared data foundations, reusable models, and interoperable tools that get better the more they’re used across the organization.
The cost of AI experiments in isolation
Experiments in isolation, no matter how clever, don’t unlock these compounding effects. A marketing team might boost productivity with a point solution, or HR might automate a workflow with a chatbot, but unless those efforts connect to the broader data, tech, and operating model, they remain local wins.
The risk is fragmentation: duplicated tools, inconsistent data, and a patchwork of pilots that can’t be scaled or sustained.
Both our experience as well research suggests that this is exactly what is going on in many organisations. A recent MIT study on the GenAI Divide for instance, found that – while AI use and adoption is spreading widely – transformation is absent. Most efforts are focused on pilots, point solutions, or isolated productivity gains. Generic tools like ChatGPT are widely used, but custom solutions stall, mainly due to integration complexity and lack of fit with workflows. And very few organizations are building the systems, processes, and governance that allow experiments to compound into lasting enterprise impact.
What happens when everyone builds?
All of this is happening fast. Decentralized. Often invisible to traditional control structures. And corporate AI leaders are realizing a hard truth: there is no way to control or centralize this movement anymore. This is the new environment, and it’s introducing a whole new layer of complexity for AI leaders.
Leaders now face a critical challenge: how to give freedom within guardrails, ensuring what happens at the edges is scalable, interoperable, and safe. Without suffocating the very experimentation that drives adoption.
It’s a critical challenge, and it’s becoming even more pressing as AI itself becomes increasingly democratized. The rise of low-code and no-code platforms and drag-and-drop model builders means that experimentation no longer requires deep technical skills. Anyone, from an HR business partner to a product marketer, can spin up an “AI solution” in an afternoon.
On the one hand, that accessibility is a gift: it fuels adoption and problem-solving across the organization. On the other hand, it also accelerates the sprawl. If every team can build their own assistant, app, or workflow without touching IT, the risk of fragmentation, security gaps, and duplicated effort only multiplies.
The trap of the traditional AI playbook
What’s clear is that this new environment of decentralized, fast-moving AI adoption needs to be governed. Without some form of coordination, the risks are obvious: fragmentation, duplicated investments, inconsistent standards, and serious security gaps. At the same time, clamping down too tightly would suffocate the very experimentation that fuels adoption in the first place.
One of the main problems is that most governance models are designed almost entirely for risk control. Committees, councils, approval boards and static guidelines communicated through powerpoint decks. Similarly, the industry-dominant AI playbook recommends organizations to start their AI journey with a centralized approach to AI/GenAI. Some consultancy firms claim that centralization ”allows to better control costs and reduces the risk of multiple teams creating similar projects’’. Our experience shows that centralization is an illusion, and it’s too slow, too static, and too rigid to guide daily AI adoption.
‘’Centralization is an illusion, and it’s too slow, too static, and too rigid to guide daily AI adoption.’’
And what we often see as a result, is that employees or functional leaders proceed anyway, experimenting with tools, vendors, and models without any consideration of the larger organizational ecosystem. The intention is good, but again, the outcome is sprawl: fragmented solutions that can’t scale, duplicate licenses, and silos that become barriers instead of enablers. Pilots without guardrails never lead to transformation. Instead, they become noise.
The invisible sprawl of costs
Another underestimated consequence of decentralized AI adoption is cost sprawl. When every team spins up its own licenses, APIs, or vendors, costs multiply quickly, and often invisibly. It’s common to see duplicate subscriptions, overlapping vendor contracts, or usage running outside official budgets. And because many of these experiments happen at the edges, much of the spend never reaches central reporting.
This is where AI FinOps becomes critical. Just as cloud transformation required a new discipline to track and optimize usage, AI governance for (Gen)AI needs real-time visibility and accountability. The challenge isn’t just the diversity of pricing models, but the lack of consistent reporting in decentralized environments, shadow IT, hidden integration costs, and fragmented spend that leaders can’t see or link to outcomes.
The blind spot: we automate everything except AI governance
Here’s the irony. Everyone is exploring AI opportunities to automate workflows and processes. But the very governance that makes AI adoption safe, scalable, and coherent? That’s still run on old-school, human-led models. In fact, we’re applying governance designed for the industrial era to a technology evolving faster than anything in recent memory. That mismatch is one of the reasons why so many organizations move slowly, even as AI races ahead.
“We’re using governance built for the industrial era to manage technology evolving faster than any innovation in memory.”
The AI-first approach to AI governance: orchestration, not control
Think of decentralized AI adoption like traffic in a modern city. If every driver just follows their own instincts, you quickly get chaos: jams, accidents, and wasted fuel. Governance shouldn’t be about stationing wardens on every corner, but about putting in traffic lights, signs, and smart sensors, i.e. light-touch guardrails that keep traffic flowing smoothly, safely, and at scale.
With an AI-first approach, governance flips its purpose. It’s not about stopping things. It’s about orchestrating flow. And only automated governance can match the speed, scale, and decentralization of AI adoption.
- Guardrails embedded in workflows through automated prompts and controls.
- Experiments logged automatically in a live registry.
- Promising use cases flagged and scaled via dashboards.
- Costs tracked in real time across teams and vendors.
- Governance itself is automated, from intake to approvals and reporting.
AI-first governance: ensuring the edge compound to value at the core
In other words, an AI-first governance model doesn’t just set rules; it bakes them into the flow of experimentation, using automation to ensure freedom at the edges compounds into value at the core. While the old governance model is about control, an AI-first governance model is about orchestration and automation. And when done right, it creates a compounding flywheel that becomes a competitive moat, shock-proofs the enterprise against regulatory or vendor disruptions, and ensures that every dollar of AI spent translates into durable enterprise capability rather than isolated wins.
A practical playbook and 90-day roadmap to build an AI-first business that operates, learns, and grows with AI at its core.

The GATE framework: making orchestration succeed
In our experience, orchestration succeeds when experimentation is guided by four elements. We integrated these factors into an easy-to-understand framework, and called it the GATE Framework. The framework works because each pillar runs on automation. Guardrails, design, training, and enablement all scale only if they are embedded and automated. That’s how orchestration keeps pace with AI itself.
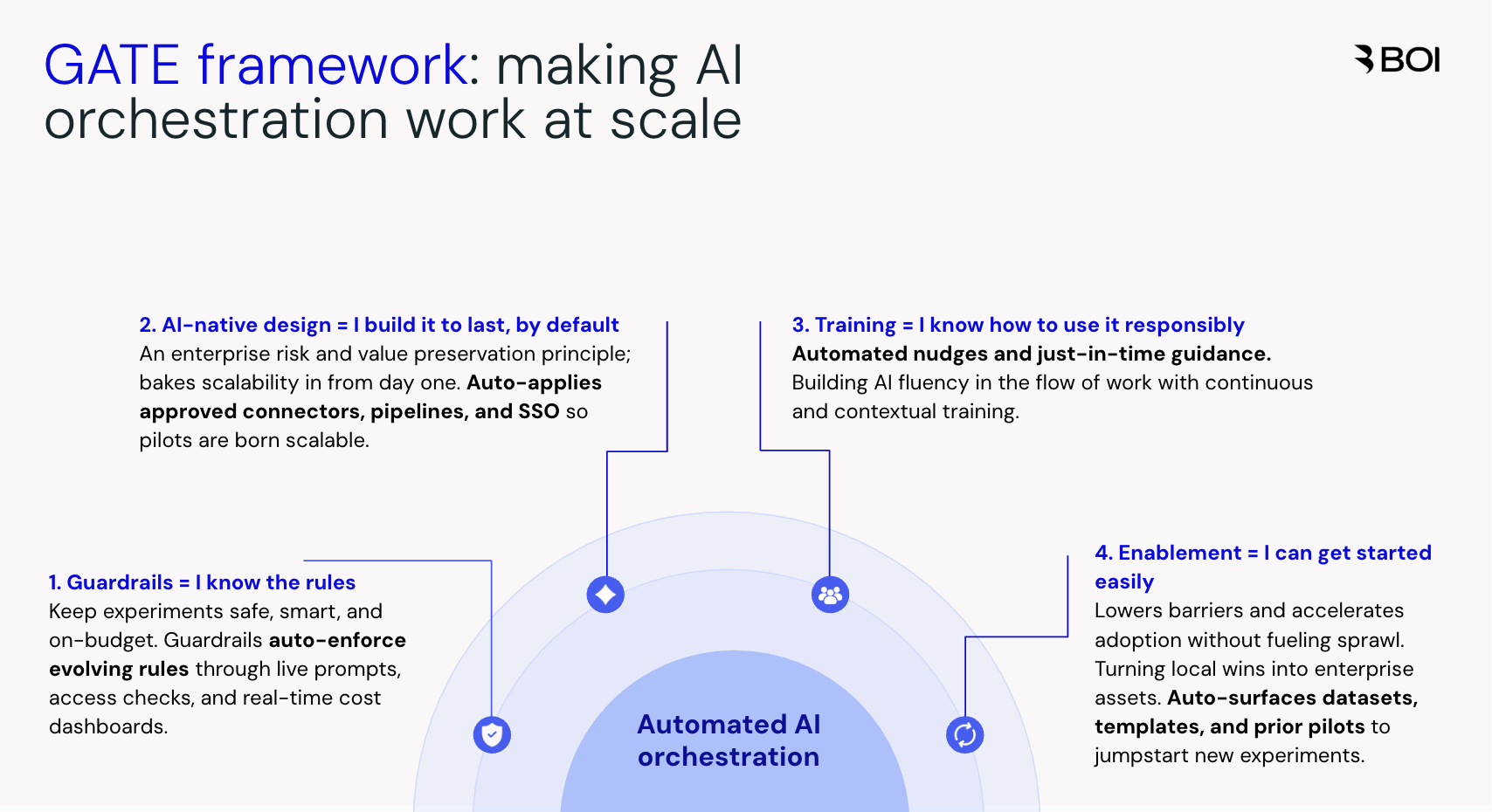
1. Guardrails = I know the rules
Guardrails are updated and enforced automatically. Prompts, access checks, and FinOps dashboards run in the background so employees don’t have to stop and interpret policy PDFs and leaders have real-time cost visibility. This surfaces not only duplication but also shows where spend aligns with impact. This keeps compliance and cost discipline at the pace of experimentation and shifts cost management from policing to value preservation, ensuring resources flow to the experiments that can graduate into enterprise capability.
Automation ensures rules evolve dynamically and are applied in real time.
2. AI-native design = I build it to last, by default
Every AI experiment should be designed with the future in mind. There is a real risk to invest in pilots that can’t be scaled because they weren’t built to integrate and scale. That’s how we’ve seen a lot of organizations lose momentum, duplicate effort, and waste investment.
AI-native design is about future-proofing your bets: ensuring that anything built at the edges has the potential to graduate into enterprise value. That means defaulting to APIs as the safe, standard way to integrate, wrapping them in pre-approved connectors that meet enterprise security and compliance standards, and running them through standard pipelines that govern how data flows, models are accessed, and outputs are monitored. Add single sign-on and embed these capabilities into everyday tools, so the compliant path is also the easiest path.
Standard pipelines and pre-approved connectors don’t just ensure security and interoperability; they also automate logging of usage and spend across vendors and teams. That means cost visibility is built into the fabric of AI adoption, rather than bolted on later. Leaders can see where money is going, compare outcomes, and make scaling decisions with confidence.
This isn’t just an IT architecture principle. It’s an enterprise risk and value preservation principle. Done right, it protects your investment and ensures that every experiment has the potential to scale rather than creating technical or organizational debt.
“Experiments should be born interoperable, not retrofitted for scale.”
3. Training = I know how to use it responsibly
Embed AI fluency into onboarding, leadership programs, and team rituals so employees feel capable of making good decisions about when and how to use AI. Instead of one-off courses, training is reinforced through automated nudges and just-in-time guidance. For example: when someone uses sensitive data, a real-time warning appears; when a pilot succeeds, the system pushes a playbook update to peers. Automation makes training continuous and contextual, so fluency grows in the flow of work, not in classrooms.
4. Enablement = I can get started easily
Lowering the barrier to experimentation is critical. Give teams sandboxes, starter kits, and a self-serve hub with approved datasets and templates so they don’t need to reinvent the wheel. But enablement is more than just starting fast; it’s also about finding and reusing what already exists.
A strong discovery system ensures that, when someone launches a new pilot, the hub automatically suggests relevant datasets, prompt libraries, or templates. Successful pilots flow automatically into the library, so that local wins become enterprise assets. Without this layer of reuse, enablement risks fueling the same sprawl it set out to fix. Automation lowers barriers and fuels reuse, preventing sprawl while accelerating adoption.
With GATE in place, local experiments and energy at the edges is more likely to compound into strategic impact rather than isolated wins.
“The art is not to slow down experiments with red tape, but to bake scale into the edges through APIs, standards, and automated checks. That’s how freedom within guardrails becomes real.”
Without proper orchestration, bottom-up AI experimentation devolves into tool sprawl and fragmentation
And without automating governance itself, it will be hard for any organization to keep pace with the very technology it seeks to harness. This is a call to abandon the industry-dominant approach to AI governance and to start recognizing that the pace and pathways of AI, as a general purpose technology, are fundamentally different from traditional IT. AI isn’t rolling out through neat, centralized programs anymore. Hence, companies need to shift the focus from control to orchestration.
The organizations that win with AI won’t be the ones running the most pilots, they’ll be the ones that can compound learnings into enterprise-wide advantage faster than their competitors. Orchestration turns scattered experiments into a flywheel, and that flywheel becomes a competitive advantage..
What’s your balance between speed at the edges and scale at the core? Let’s talk.

Managing Director of Data & AI
Laura Stevens, PhD, is the Managing Director of Data & AI, bringing a unique blend of strategic vision, analytical expertise, and leadership acumen. With a background in neuropsychology, business consulting and organizational transformation, she has successfully navigated a career spanning academia, consulting, and industry leadership. As a former VP Data & AI in an international organization, Laura has led large-scale Data & AI teams covering data science, machine learning, data engineering, data governance, and visualization. She is passionate about leading organizations through their data & AI transformation.